
The mathematical computing behind generative AI is extremely complex and has serious bottlenecks in memory bandwidth and capacity. Therefore, many companies are constantly launching solutions, hoping to solve the problem of insufficient HBM memory capacity.
Hua Feng, deputy president of data storage products, pointed out that AI reasoning currently faces three major problems: "unstop pushing" (the input content is too long and beyond the processing scope), "slow pushing" (the response speed is too slow), and "promoting" (the calculation cost is too high).
Generally speaking, the memory server will use the new high-speed interface protocol CXL extension system main memory to connect more external memory, so that the number of TB of DDR main memory is integrated to form a cache with relatively fast speed and large capacity, and is paired with HBM with extremely high frequency width, fast reading, but relatively limited capacity, for AI workload.

(Source: Smart Things)
According to the memory requirements mentioned by Hua, it is mainly divided into HBM, DRAM and SSD. Among them, HBM mainly stores real memory data, with a capacity of about 10GB to 10GB, mainly for extremely hot data and real-time dialogue; DRAM is used as short-term memory data, with a capacity of about 10GB to TB, mainly for hot data and multi-wheel dialogue; SSD long-term memory data and external knowledge, with a capacity of about TB to PB, mainly for hot data, such as historical dialogue, RAG knowledge database, and essay database.
What is KV cache?Before sharing the solutions of various memory, understand what "KV Cache" is?
In the AI reasoning stage, a "attention mechanism" similar to the human brain will be used, including remembering the important parts of the query (Key) and the important parts of the context (Value) in order to answer the prompts.
If each new token is processed, the model must recalculate the importance (Key and Value) of each word to all previously processed tokens to update attention. In other words, it is like a student who has to read a new sentence and read the entire article again, which is quite time-consuming.
Therefore, the Big Language Model (LLM) is added to a mechanism called "KV Cache", which can store previous important information (Key and Value) in the memory, eliminating the cost of each recalculation, thereby increasing the token processing and generation speed by several levels.
If taking the sentences just now, the concept of KV cache is similar to the notion of a notebook can record important information. When there is a new token, there is no need to look back again. You can calculate the new attention weight directly from the information in the notebook.
What are the advantages of short-term memory for AI models?According to Micron's official website, KV cache is a "short-term memory of AI models", which allows the model to remember what has been processed in previous issues. In this way, every time a user reopens the previous discussion or asks a new question, there is no need to start recalculating from the beginning.
With KV cache, AI can understand what users have said, reasoned, and provided at any time, and provide faster and more tangible answers to these longer and more in-depth discussions.
KV cache can bring a variety of advantages, such as near-instant response capabilities, long-format language, and can also use the GPU more efficiently by continuously storing KV caches in the storage device for reuse. In addition, a wide range of users' cloud services can be provided, so that each user's query is connected to the correct reference and keeps running smoothly.
However, the longer the context, the larger the cache is needed. Even for medium-sized models, KV cache will rapidly expand to more than GB per session, so the solution to KV cache has become one of the focus of attention from all companies.
How do each company solve the problem of KV cache demand and insufficient memory?Due to the restrictions on exports from the United States, it is difficult for China to obtain key resources such as HBM. Therefore, China recently launched a new software tool called Unified Cache Manager (simplified UCM), which can accelerate training and reasoning of large language models (LLMs) without using HBM.
UCM is a reasoning acceleration suite centered on "KV Cache", which integrates multiple cache acceleration algorithm tools to manage the KV cache memory data generated during the inference process, expand the reasoning context window, realize high throughput and low delay inference experience, and reduce the inference cost per token.
The software allocates AI data between HBM, standard DRAM and SSD based on the delay characteristics of different memory types and the delay requirements of various AI applications.

(Source: Smart Things)
Among them, UCM is divided into three parts. The top layer is through "Connector" to connect with the diversified engines and diversified computing power in the industry, such as Huasheng, NVIDIA, etc.; and then through the middle layer "Memory Management" (Accelerator) and KV Cache dynamic multi-level management, splitting the algorithm into a suitable method for fast computing, making computing more efficient; finally, "Adapter", which combines the storage interface card with professional sharing to read and write data in a more efficient way, reducing waiting time.
With a large number of tests and verifications, UCM can reduce the time delay of the first token by up to 90%, increase the system throughput by 22 times, and achieve 10 times level context window expansion.
NVIDIA supports new Enfabrica launching "EMFASYS"Enfabrica, a new chip company supported by NVIDIA, recently officially launched a system with "EMFASYS" software with "ACF-S" chips, with the goal of reducing the high memory costs of data centers.
Foreign media The Next Platform believes that if KV cache used in AI reasoning core can be accelerated, it is expected to become a "hands-level application" that Enfabrica and its peers have been waiting for for a long time. According to reports, the memory is currently a big bottle of zombies, and having an oversized shared memory pool that can run at the speed of the host memory and is enough to store KV vectors and embeddings is one of the ways to make reasoning run faster and cheaper.
ACF-S chip (also known as SuperNIC) is essentially an interchange chip that combines Ethernet and PCI-Express/CXL.
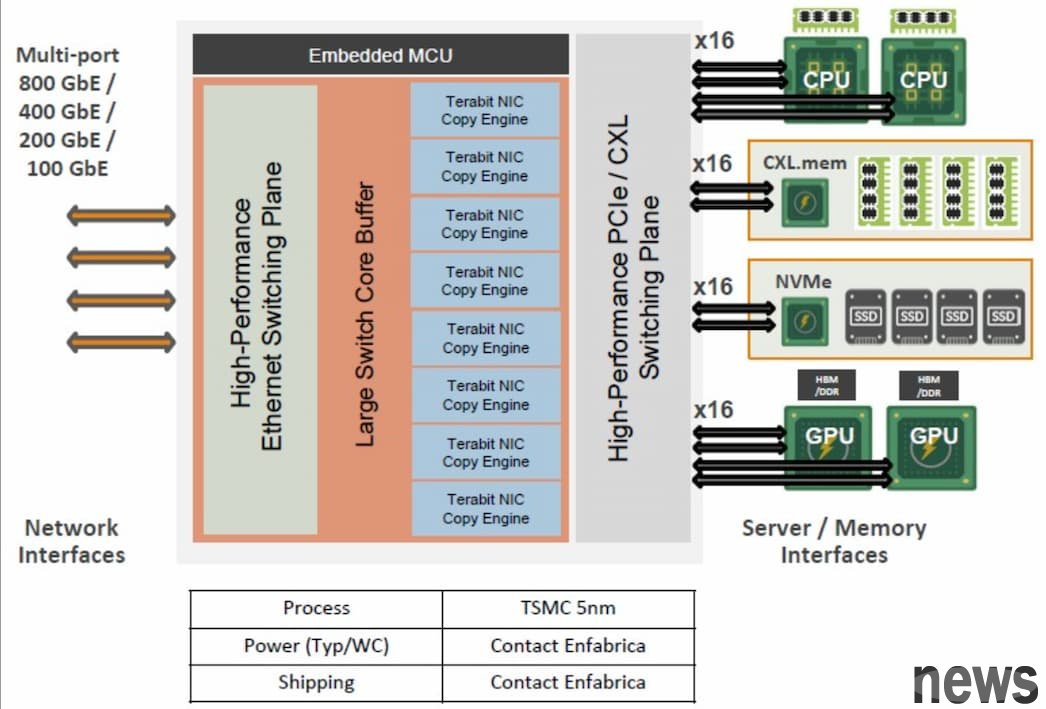
(Source: The Next Platform)
Enfabrica founder and executive director Rochan Sankar pointed out that the design core of this system is its own developed dedicated network chip, which allows the AI computing chip to be directly connected to equipment equipped with DDR5 memory specifications. Although the DDR5 is not as fast as HBM, the price is much cheaper.
Enfabrica's trial image reduces memory costs through innovative architectures. The company uses its own developed dedicated software to transmit data between AI chips and a large number of low-cost memory, thereby effectively controlling costs while ensuring the performance of the data center.
EMFASYS is mainly an independent memory accelerator and expander that is responsible for AI inference work, but it may be just one of the applications of ACF-S chip sets. In the future, it is not ruled out that the NVLink Fusion I/O chip version can be directly connected to SuperNIC.
The following is the memory system of EMFASYS. This is mainly one of the specially configured applications, specially used to expand the memory capacity of the GPU and XPU in the system.
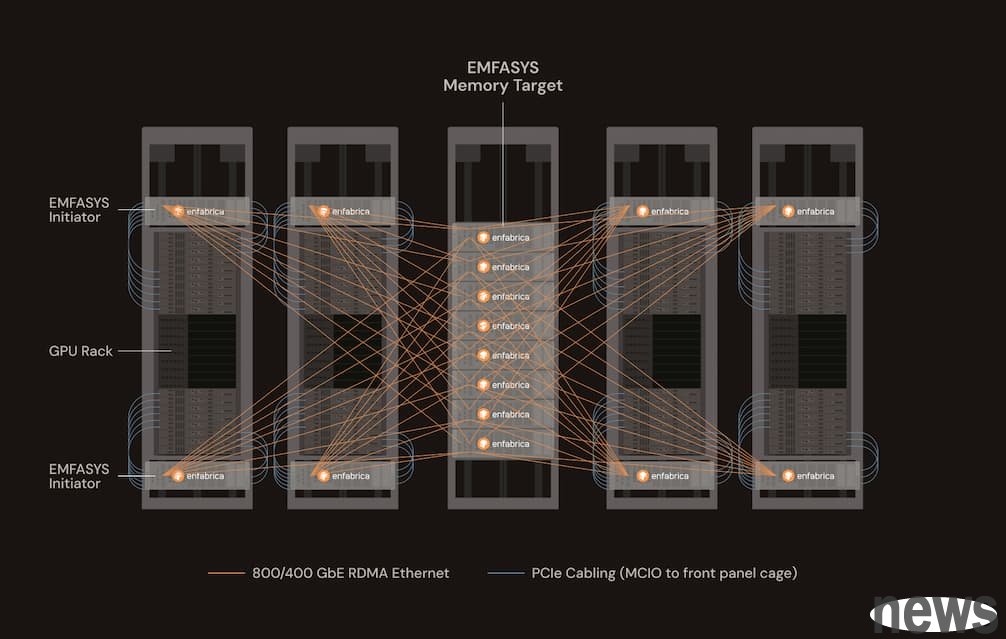
(Source: The Next Platform)
In the middle rack, EMFASYS memory servers are placed, and there are eight units in each rack. Each memory server has nine SuperNICs installed internally. Each SuperNIC provides two CXL memory DIMM channels and provides a total of 18TB of DDR5 main memory capacity through two 1TB DIMMs per channel.
Currently, EMFASYS machines can support 18 memory channels, and will be upgraded to 28 channels next year. The following picture shares how KV cache is connected.
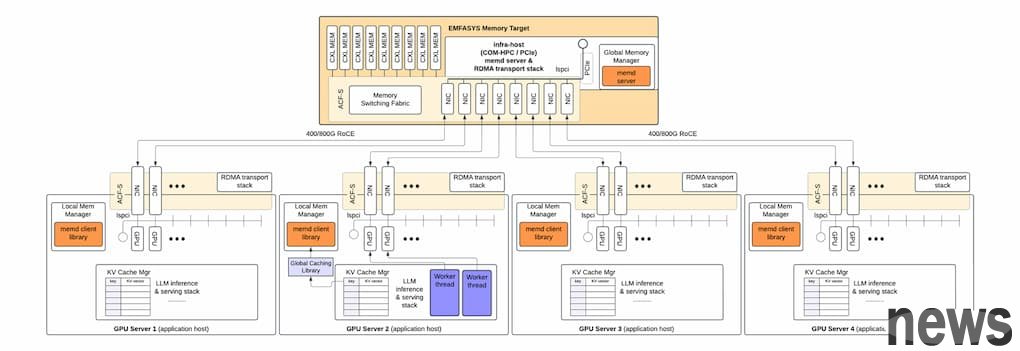
(Source: The Next Platform)
Executive Director Rochan Sankar noted, "We basically build a traditional cloud storage target system with a large amount of memory, and set up dozens of ports on the chip to spread the transaction lines across all memory. If there is an ultra-wide memory controller that can spread the writes into all channels, your data can be maximized as needed and written in at the same time with all ports. For example, transferring a 100GB The file can take a very short time depending on the number of connections used and the number of memory channels."
Skimpy HBM Memory Opens Up The Way For AI Inference Memory Godbox Micron's official website: From popular language to the end: Understand the "reason" behind KV cache in AI Extended reading: In order to publish the new AI technology "UCM", the speed of destruction of HBM and AI reasoning has increased by 90%. New model R2 is the main reason for delaying the delay! DeepSeek tried to fail because the chip was still up to NVIDIA